#graph rag llm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
#graphrag#esg sustainability#semantic graph model#esg domains#knowledge graph llm#esg and nlp#graph rag llm
0 notes
Text
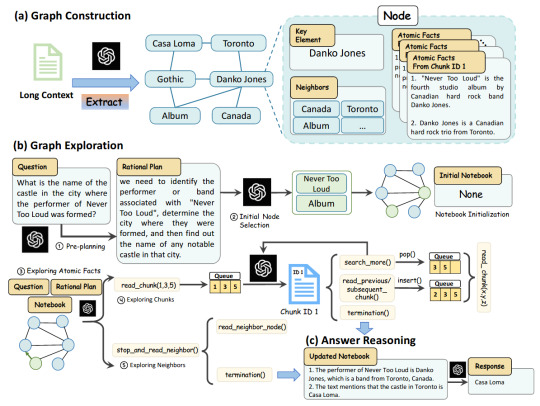
GraphReader approach, consisting of graph construction, graph exploration, andanswer reasoning
2 notes
·
View notes
Text
Developer - L3
Job title: Developer – L3 Company: Wipro Job description: Secondary skill Chatbot, RAG Pipelines JD 1. GEN AI , LLM, NLP- Python 2. Lang Chain and Lang Graph 3. Chatbot, RAG… Expected salary: Location: Pune, Maharashtra Job date: Mon, 09 Jun 2025 00:28:52 GMT Apply for the job now!
0 notes
Text
Can AI Truly Develop a Memory That Adapts Like Ours?

Human memory is a marvel. It’s not just a hard drive where information is stored; it’s a dynamic, living system that constantly adapts. We forget what's irrelevant, reinforce what's important, connect new ideas to old ones, and retrieve information based on context and emotion. This incredible flexibility allows us to learn from experience, grow, and navigate a complex, ever-changing world.
But as Artificial Intelligence rapidly advances, particularly with the rise of powerful Large Language Models (LLMs), a profound question emerges: Can AI truly develop a memory that adapts like ours? Or will its "memory" always be a fundamentally different, and perhaps more rigid, construct?
The Marvel of Human Adaptive Memory
Before we dive into AI, let's briefly appreciate what makes human memory so uniquely adaptive:
Active Forgetting: We don't remember everything. Our brains actively prune less relevant information, making room for new and more critical knowledge. This isn't a bug; it's a feature that prevents overload.
Reinforcement & Decay: Memories strengthen with use and emotional significance, while unused ones fade. This is how skills become second nature and important lessons stick.
Associative Learning: New information isn't stored in isolation. It's linked to existing knowledge, forming a vast, interconnected web. This allows for flexible retrieval and creative problem-solving.
Contextual Recall: We recall memories based on our current environment, goals, or even emotional state, enabling highly relevant responses.
Generalization & Specialization: We learn broad patterns (generalization) and then refine them with specific details or exceptions (specialization).
How AI "Memory" Works Today (and its Limitations)
Current AI models, especially LLMs, have impressive abilities to recall and generate information. However, their "memory" mechanisms are different from ours:
Context Window (Short-Term Memory): When you interact with an LLM, its immediate "memory" is typically confined to the current conversation's context window (e.g., Claude 4's 200K tokens). Once the conversation ends or the context window fills, the older parts are "forgotten" unless explicitly saved or managed externally.
Fine-Tuning (Long-Term, Static Learning): To teach an LLM new, persistent knowledge or behaviors, it must be "fine-tuned" on specific datasets. This is like a complete retraining session, not an adaptive, real-time learning process. It's costly and not continuous.
Retrieval-Augmented Generation (RAG): Many modern AI applications use RAG, where the LLM queries an external database of information (e.g., your company's documents) to retrieve relevant facts before generating a response. This extends knowledge beyond the training data but isn't adaptive learning; it's smart retrieval.
Knowledge vs. Experience: LLMs learn from vast datasets of recorded information, not from "lived" experiences in the world. They lack the sensorimotor feedback, emotional context, and physical interaction that shape human adaptive memory.
Catastrophic Forgetting: A major challenge in continual learning, where teaching an AI new information causes it to forget previously learned knowledge.
The Quest for Adaptive AI Memory: Research Directions
The limitations of current AI memory are well-recognized, and researchers are actively working on solutions:
Continual Learning / Lifelong Learning: Developing AI architectures that can learn sequentially from new data streams without forgetting old knowledge, much like humans do throughout their lives.
External Memory Systems & Knowledge Graphs: Building sophisticated external memory banks that AIs can dynamically read from and write to, allowing for persistent and scalable knowledge accumulation. Think of it as a super-smart, editable database for AI.
Neuro-Symbolic AI: Combining the pattern recognition power of deep learning with the structured knowledge representation of symbolic AI. This could lead to more robust, interpretable, and adaptable memory systems.
"Forgetting" Mechanisms in AI: Paradoxically, building AI that knows what to forget is crucial. Researchers are exploring ways to implement controlled decay or pruning of irrelevant or outdated information to improve efficiency and relevance.
Memory for Autonomous Agents: For AI agents performing long-running, multi-step tasks, truly adaptive memory is critical. Recent advancements, like Claude 4's "memory files" and extended thinking, are steps in this direction, allowing agents to retain context and learn from past interactions over hours or even days.
Advanced RAG Integration: Making RAG systems more intelligent – not just retrieving but also updating and reasoning over the knowledge store based on new interactions or data.
Challenges and Ethical Considerations
The journey to truly adaptive AI memory is fraught with challenges:
Scalability: How do you efficiently manage and retrieve information from a dynamically growing, interconnected memory that could be vast?
Bias Reinforcement: If an AI's memory adapts based on interactions, it could inadvertently amplify existing biases in data or user behavior.
Privacy & Control: Who owns or controls the "memories" of an AI? What are the implications for personal data stored within such systems?
Interpretability: Understanding why an AI remembers or forgets certain pieces of information, especially in critical applications, becomes complex.
Defining "Conscious" Memory: As AI memory becomes more sophisticated, it blurs lines into philosophical debates about consciousness and sentience.
The Future Outlook
Will AI memory ever be exactly like ours, complete with subjective experience, emotion, and subconscious associations? Probably not, and perhaps it doesn't need to be. The goal is to develop functionally adaptive memory that enables AI to:
Learn continuously: Adapt to new information and experiences in real-time.
Retain relevance: Prioritize and prune knowledge effectively.
Deepen understanding: Form rich, interconnected knowledge structures.
Operate autonomously: Perform complex, long-running tasks with persistent context.
Recent advancements in models like Claude 4, with its "memory files" and extended reasoning, are exciting steps in this direction, demonstrating that AI is indeed learning to remember and adapt in increasingly sophisticated ways. The quest for truly adaptive AI memory is one of the most fascinating and impactful frontiers in AI research, promising a future where AI systems can truly grow and evolve alongside us.
0 notes
Text
Mistral OCR 25.05, Mistral AI Le Chat Enterprise on Google

Google Cloud offers Mistral AI’s Le Chat Enterprise and OCR 25.05 models.
Google Cloud provides consumers with an open and adaptable AI environment to generate customised solutions. As part of this commitment, Google Cloud has upgraded AI solutions with Mistral AI.
Google Cloud has two Mistral AI products:
Google Cloud Marketplace’s Le Chat Enterprise
Vertex AI Mistral OCR 25.05
Google Cloud Marketplace Mistral AI Le Chat Enterprise
Le Chat Enterprise is a feature-rich generative AI work assistant. Available on Google Cloud Marketplace. Its main purpose is to boost productivity by integrating technologies and data.
Le Chat Enterprise offers many functions on one platform, including:
Custom data and tool integrations (Google Drive, Sharepoint, OneDrive, Google Calendar, and Gmail initially, with more to follow, including templates)
Enterprise search
Agents build
Users can create private document libraries to reference, extract, and analyse common documents from Drive, Sharepoint, and uploads.
Personalised models
Implementations hybrid
Further MCP support for corporate system connectivity; Auto Summary for fast file viewing and consumption; secure data, tool connections, and libraries
Mistral AI’s Medium 3 model powers Le Chat Enterprise. AI productivity on a single, flexible, and private platform is its goal. Flexible deployment choices like self-hosted, in your public or private cloud, or as a Mistral cloud service let you choose the optimal infrastructure without being locked in. Data is protected by privacy-first data connections and strict ACL adherence.
The stack is fully configurable, from models and platforms to interfaces. Customisation includes bespoke connectors with company data, platform/model features like user feedback loops for model self-improvement, and assistants with stored memories. Along with thorough audit logging and storage, it provides full security control. Mistral’s AI scientists and engineers help deliver value and improve solutioning.
Example Le Chat Enterprise use cases:
Agent creation: Users can develop and implement context-aware, no-code agents.
Accelerating research and analysis: Summarises large reports, extracts key information from documents, and conducts brief web searches.
Producing actionable insights: It can automate financial report production, produce text-to-SQL queries for financial research, and turn complex data into actionable insights for finance.
Accelerates software development: Code generation, review, technical documentation, debugging, and optimisation.
Canvas improves content production by letting marketers interact on visuals, campaign analysis, and writing.
For scalability and security, organisations can use Le Chat Enterprise on the Google Cloud Marketplace. It integrates to Google Cloud services like BigQuery and Cloud SQL and facilitates procurement.
Contact Mistral AI sales and visit the Le Chat Enterprise Google Cloud Marketplace page to use Mistral’s Le Chat Enterprise. The Mistral AI announcement has further details. Le Chat (chat.mistral.ai) and their mobile apps allow free trial use.
OCR 25.05 model llm Mistral
One new OCR API is Mistral OCR 25.05. Vertex AI Model Garden has it. This model excels at document comprehension. It raises the bar in this discipline and can cognitively interpret text, media, charts, tables, graphs, and equations in content-rich papers. From PDFs and photos, it retrieves organised interleaved text and visuals.
Cost of Mistral OCR?
With a Retrieval Augmented Generation (RAG) system that takes multimodal documents, Mistral OCR is considered the ideal model. Additionally, millions of Le Chat users use Mistral OCR as their default document interpretation model. Mistral’s Platform developer suite offers the Mistral-ocr-latest API, which will soon be offered on-premises and to cloud and inference partners. The API costs 1000 pages/$ (double with batch inference).
Highlights of Mistral OCR include:
Cutting-edge comprehension of complex papers, including mathematical formulas, tables, interleaved images, and LaTeX formatting, helps readers understand rich content like scientific articles.
This system is multilingual and multimodal, parsing, understanding, and transcribing thousands of scripts, fonts, and languages. This is crucial for global and hyperlocal businesses.
Excellent benchmarks: This model consistently outperforms top OCR models in rigorous benchmark tests. Compared to Google Document AI, Azure OCR, Gemini models, and GPT-4o, Mistral OCR 2503 scores highest in Overall, Math, Multilingual, Scanned, and Tables accuracy. It also has the highest Fuzzy Match in Generation and multilingual scores compared to Azure OCR, Google Doc AI, and Gemini-2.0-Flash-001. It extracts embedded images and text, unlike other LLMs in the benchmark.
The lightest and fastest in its class, processing 2000 pages per minute on a single node.
Structured output called “doc-as-prompt” uses documents as prompts for powerful, clear instructions. This allows data to be extracted and formatted into structured outputs like JSON, which may be linked into function calls to develop agents.
Organisations with high data protection needs for classified or sensitive information might self-host within their own infrastructure.
Example of Mistral OCR 25.05
Use cases for Mistral OCR 25.05 include:
Digitising scientific research: Making articles and journals AI-ready for downstream intelligence engines streamlines scientific procedures.
Preservation and accessibility can be achieved by digitising historical records and artefacts.
Simplifying customer support: indexing manuals and documentation to improve satisfaction and response times.
AI literature preparation in various fields: We help businesses convert technical literature, engineering drawings, lecture notes, presentations, regulatory filings, and more into indexed, answer-ready formats to gain insights and enhance productivity across vast document volumes.
Integrating Mistral OCR 25.05 as a MaaS on Vertex AI creates a full AI platform. It provides enterprise-grade security and compliance for confident growth and fully controlled infrastructure. The Vertex AI Model Garden includes over 200 foundation models, including Mistral OCR 25.05, so customers can choose the best one for their needs. Vertex AI now offers Mistral OCR 25.05, along with Anthropic models Claude Opus 4 and Claude Sonnet 4.
To develop using Mistral OCR 25.05 on Vertex AI, users must go to the model card in the Model Garden, click “Enable,” and follow the instructions. Platform users can access the API, and Le Chat users can try Mistral OCR for free.
#MistralOCR#LeChatEnterprise#MistralOCR2505#MistralAILeChatEnterprise#MistralOCRmodel#Mistralocr2505modelllm#technology#technews#news#technologynews#govindhtech
1 note
·
View note
Text
Generative AI in Customer Service Explained: The Technology, Tools, and Trends Powering the Future of Customer Support?
Customer service is undergoing a radical transformation, fueled by the rise of Generative AI. Gone are the days when customer queries relied solely on static FAQs or long wait times for human agents. With the emergence of large language models and AI-driven automation, businesses are now delivering faster, smarter, and more personalized support experiences.

But how exactly does generative AI work in customer service? What tools are leading the change? And what trends should you watch for?
Let’s explore the technology, tools, and trends that are powering the future of customer support through generative AI.
1. What Is Generative AI in Customer Service?
Generative AI refers to AI systems that can generate human-like responses, ideas, or content based on trained data. In customer service, it means AI tools that can:
Understand and respond to customer queries in real time
Provide contextual, conversational assistance
Summarize long interactions
Personalize responses based on customer history
Unlike traditional rule-based chatbots, generative AI adapts dynamically, making interactions feel more human and engaging.
2. Core Technologies Powering Generative AI in Support
A. Large Language Models (LLMs)
LLMs like GPT-4, Claude, and Gemini are the foundation of generative AI. Trained on massive datasets, they understand language context, tone, and nuances, enabling natural interactions with customers.
B. Natural Language Processing (NLP)
NLP allows machines to comprehend and interpret human language. It's what enables AI tools to read tickets, interpret intent, extract sentiment, and generate suitable responses.
C. Machine Learning (ML) Algorithms
ML helps customer service AI to learn from past interactions, identify trends in support tickets, and improve performance over time.
D. Knowledge Graphs and RAG (Retrieval-Augmented Generation)
These enhance the factual accuracy of AI outputs by allowing them to pull relevant data from enterprise databases, manuals, or FAQs before generating responses.
3. Popular Generative AI Tools in Customer Service
Here are some of the leading tools helping companies implement generative AI in their support workflows:
1. Zendesk AI
Integrates generative AI to assist agents with reply suggestions, automatic ticket summarization, and knowledge article recommendations.
2. Freshdesk Copilot
Freshworks’ AI copilot helps agents resolve issues by summarizing customer conversations and recommending next steps in real-time.
3. Salesforce Einstein GPT
Einstein GPT offers generative AI-powered replies across CRM workflows, including customer support, with real-time data from Salesforce’s ecosystem.
4. Intercom Fin AI Agent
Designed to fully automate common customer queries using generative AI, Fin delivers highly accurate answers and passes complex tickets to agents when necessary.
5. Ada
An automation platform that uses generative AI to build customer flows without coding, Ada enables instant support that feels personal.
4. Top Use Cases of Generative AI in Customer Support
✅ 24/7 Automated Support
Generative AI enables round-the-clock support without human intervention, reducing reliance on night shift teams.
✅ Ticket Summarization
AI can summarize lengthy email or chat threads, saving agents time and enabling faster resolution.
✅ Response Drafting
AI can instantly draft professional replies that agents can review and send, speeding up response times.
✅ Knowledge Article Creation
Generative models can help generate and update help articles based on customer queries and ticket data.
✅ Intent Detection and Routing
AI detects the user's intent and routes the query to the right department or agent, reducing miscommunication and wait times.
5. Business Benefits of Generative AI in Customer Service
Increased Efficiency: AI reduces the time spent on repetitive queries and ticket categorization.
Cost Savings: Fewer agents are required to manage high ticket volumes.
Improved CX: Customers get faster, more accurate answers—often without needing to escalate.
Scalability: AI handles volume spikes without service dips.
Continuous Learning: AI models improve over time with every new interaction.
6. Emerging Trends Shaping the Future
1. AI-Human Hybrid Support
Companies are combining generative AI with human oversight. AI handles simple queries while humans address emotional or complex issues.
2. Multilingual Support
LLMs are becoming fluent in multiple languages, enabling instant global customer support without translation delays.
3. Emotionally Intelligent AI
AI is beginning to detect customer tone and sentiment, allowing it to adjust responses accordingly—being empathetic when needed.
4. Voice-Powered AI Agents
Voice bots powered by generative AI are emerging as a new frontier, delivering seamless spoken interactions.
5. Privacy-Compliant AI
With regulations like GDPR, companies are deploying AI models with built-in privacy filters and localized deployments (e.g., Private LLMs).
7. Challenges and Considerations
Despite the advantages, generative AI in customer service comes with some challenges:
Hallucinations (Inaccurate Responses): LLMs can sometimes fabricate answers if not grounded in verified knowledge sources.
Data Security Risks: Sharing sensitive customer data with third-party models can raise compliance issues.
Need for Continuous Training: AI systems must be regularly updated to stay relevant and accurate.
Enterprises must monitor, fine-tune, and regulate AI systems carefully to maintain brand trust and service quality.
8. The Road Ahead: What to Expect
The future of customer service is AI-augmented, not AI-replaced. As generative AI tools mature, they’ll shift from assisting to proactively resolving customer needs—automating complex workflows like returns, disputes, and onboarding. Businesses that embrace this evolution today will lead in both cost-efficiency and customer satisfaction tomorrow.
Conclusion
Generative AI in customer service is redefining what excellent customer service looks like—making it faster, more personalized, and increasingly autonomous. Whether you're a startup or a global brand, adopting these tools early can offer a serious competitive edge.
0 notes
Text
AI Agent Development: A Complete Guide to Building Smart, Autonomous Systems in 2025
Artificial Intelligence (AI) has undergone an extraordinary transformation in recent years, and 2025 is shaping up to be a defining year for AI agent development. The rise of smart, autonomous systems is no longer confined to research labs or science fiction — it's happening in real-world businesses, homes, and even your smartphone.
In this guide, we’ll walk you through everything you need to know about AI Agent Development in 2025 — what AI agents are, how they’re built, their capabilities, the tools you need, and why your business should consider adopting them today.

What Are AI Agents?
AI agents are software entities that perceive their environment, reason over data, and take autonomous actions to achieve specific goals. These agents can range from simple chatbots to advanced multi-agent systems coordinating supply chains, running simulations, or managing financial portfolios.
In 2025, AI agents are powered by large language models (LLMs), multi-modal inputs, agentic memory, and real-time decision-making, making them far more intelligent and adaptive than their predecessors.
Key Components of a Smart AI Agent
To build a robust AI agent, the following components are essential:
1. Perception Layer
This layer enables the agent to gather data from various sources — text, voice, images, sensors, or APIs.
NLP for understanding commands
Computer vision for visual data
Voice recognition for spoken inputs
2. Cognitive Core (Reasoning Engine)
The brain of the agent where LLMs like GPT-4, Claude, or custom-trained models are used to:
Interpret data
Plan tasks
Generate responses
Make decisions
3. Memory and Context
Modern AI agents need to remember past actions, preferences, and interactions to offer continuity.
Vector databases
Long-term memory graphs
Episodic and semantic memory layers
4. Action Layer
Once decisions are made, the agent must act. This could be sending an email, triggering workflows, updating databases, or even controlling hardware.
5. Autonomy Layer
This defines the level of independence. Agents can be:
Reactive: Respond to stimuli
Proactive: Take initiative based on context
Collaborative: Work with other agents or humans
Use Cases of AI Agents in 2025
From automating tasks to delivering personalized user experiences, here’s where AI agents are creating impact:
1. Customer Support
AI agents act as 24/7 intelligent service reps that resolve queries, escalate issues, and learn from every interaction.
2. Sales & Marketing
Agents autonomously nurture leads, run A/B tests, and generate tailored outreach campaigns.
3. Healthcare
Smart agents monitor patient vitals, provide virtual consultations, and ensure timely medication reminders.
4. Finance & Trading
Autonomous agents perform real-time trading, risk analysis, and fraud detection without human intervention.
5. Enterprise Operations
Internal copilots assist employees in booking meetings, generating reports, and automating workflows.
Step-by-Step Process to Build an AI Agent in 2025
Step 1: Define Purpose and Scope
Identify the goals your agent must accomplish. This defines the data it needs, actions it should take, and performance metrics.
Step 2: Choose the Right Model
Leverage:
GPT-4 Turbo or Claude for text-based agents
Gemini or multimodal models for agents requiring image, video, or audio processing
Step 3: Design the Agent Architecture
Include layers for:
Input (API, voice, etc.)
LLM reasoning
External tool integration
Feedback loop and memory
Step 4: Train with Domain-Specific Knowledge
Integrate private datasets, knowledge bases, and policies relevant to your industry.
Step 5: Integrate with APIs and Tools
Use plugins or tools like LangChain, AutoGen, CrewAI, and RAG pipelines to connect agents with real-world applications and knowledge.
Step 6: Test and Simulate
Simulate environments where your agent will operate. Test how it handles corner cases, errors, and long-term memory retention.
Step 7: Deploy and Monitor
Run your agent in production, track KPIs, gather user feedback, and fine-tune the agent continuously.
Top Tools and Frameworks for AI Agent Development in 2025
LangChain – Chain multiple LLM calls and actions
AutoGen by Microsoft – For multi-agent collaboration
CrewAI – Team-based autonomous agent frameworks
OpenAgents – Prebuilt agents for productivity
Vector Databases – Pinecone, Weaviate, Chroma for long-term memory
LLMs – OpenAI, Anthropic, Mistral, Google Gemini
RAG Pipelines – Retrieval-Augmented Generation for knowledge integration
Challenges in Building AI Agents
Even with all this progress, there are hurdles to be aware of:
Hallucination: Agents may generate inaccurate information.
Context loss: Long conversations may lose relevancy without strong memory.
Security: Agents with action privileges must be protected from misuse.
Ethical boundaries: Agents must be aligned with company values and legal standards.
The Future of AI Agents: What’s Coming Next?
2025 marks a turning point where AI agents move from experimental to mission-critical systems. Expect to see:
Personalized AI Assistants for every employee
Decentralized Agent Networks (Autonomous DAOs)
AI Agents with Emotional Intelligence
Cross-agent Collaboration in real-time enterprise ecosystems
Final Thoughts
AI agent development in 2025 isn’t just about automating tasks — it’s about designing intelligent entities that can think, act, and grow autonomously in dynamic environments. As tools mature and real-time data becomes more accessible, your organization can harness AI agents to unlock unprecedented productivity and innovation.
Whether you’re building an internal operations copilot, a trading agent, or a personalized shopping assistant, the key lies in choosing the right architecture, grounding the agent in reliable data, and ensuring it evolves with your needs.
1 note
·
View note
Link
看看網頁版全文 ⇨ 雜談:到底要怎麼使用RAGFlow呢? / TALK: RAGFlow Drained All My Resources https://blog.pulipuli.info/2025/03/talk-ragflow-drained-all-my-resources.html 由於這次RAGFlow看起來又無法順利完成任務了,我還是來記錄一下目前的狀況吧。 ---- # 專注做好RAG的RAGFlow / RAGFlow: Focusing on RAG。 https://ragflow.io/ 在眾多LLM DevOps的方案中,RAGFlow也絕對可以算得上是重量級的那邊。 相較於其他方案,RAGFlow一直積極加入各種能夠改進RAG的特殊技術,使得它在RAG的應用方面出類拔萃。 RAGFlow的主要特色包括了: 1. 文件複雜排版分析功能:能夠解讀表格,甚至能分析PDF裡面圖片的文字。 2. 分層摘要RAPTOR。能改善RAG用分段(chunking)切斷資訊的問題。 3. 結合知識圖譜的GraphRAG跟LightRAG。讓回答著重與命名實體,而且還可能找到詞彙之間的隱含關係。 4. 能作為Dify外部知識庫使用。 不過,除了第四點之外,要做到前三項功能,目前看起來還有很多問題需要克服。 # 硬體要求 / Hardware Requirements。 由於運作RAGFlow會使用OCR來分析文件的排版,記憶體最好是給到16GB之多,硬碟空間也需要準備50GB。 這真的是重量級的方案。 如果這些準備好的話,要做到分析複雜排版文件的這件事情就不是很難了。 只要做到這個程度,RAGFlow就能在回答引用時顯示來源的文件位置。 這樣幫助就很大了呢。 # 大量請求的難題 / The Challenge of Numerous Requests。 相較於排版分析是RAGFlow組件中的功能,RAPTOR跟Knowledge Graph都要搭配大型語言模型才能解析跟查詢資料。 而RAGFlow在處理資料的時候會在短時間內發送大量的API請求,很容易就被rate limit限流。 既然直接連接LLM API會因為太多請求而被限流,我就試著改轉接到Dify上,並在API請求的時候加上排隊等候的機制。 Dify裡面雖然可以寫程式碼,但他其實也是在沙盒裡面運作的程式,還是有著不少的限制。 其中一個限制就是不能讓我直接修改系統上的檔案。 因此如果要在Dify內用程式讀寫資料,用HTTP請求傳送可能是比較好的做法。 這些做法花了很多時間調整。 調整了老半天,總算能夠讓它正常運作。 不過過了一陣子,LLM API連回應沒有反應了。 我猜想可能是連接的Gemini API已經超過用量而被禁止吧。 ---- 繼續閱讀 ⇨ 雜談:到底要怎麼使用RAGFlow呢? / TALK: RAGFlow Drained All My Resources https://blog.pulipuli.info/2025/03/talk-ragflow-drained-all-my-resources.html
0 notes
Text
Early in my career, I became obsessed with relational databases. There was something uniquely elegant about the way they transformed data into structured, accessible information. IBM’s "A Relational Model of Data for Large Shared Data Banks," written by Edgar F. Codd in the 1970s, was a breakthrough that revolutionized how we approached data storage and management. The concept of tables, columns, and rows abstracted the complexities of data storage, making it possible for non-technical users to interact with information without needing to understand the inner workings of the system.
Relational databases unlocked data democratization. They enabled businesses to make decisions with real-time access to information, integrating this capability into ERP, CRM, and e-commerce systems. This data-driven approach catalyzed the digital transformation of industries, allowing them to scale efficiently. It wasn’t just the access that excited me—it was how these databases fundamentally altered the way we thought about information management, building the foundations for modern enterprise systems.
Evolution in Data Persistence: Exploring the Limits
As my career progressed, I delved deeper into various types of data persistence beyond relational databases. Graph databases offered new ways to explore relationships between entities. HBase, with its distributed storage model, provided a scalable option for managing vast amounts of data. Timeseries databases like Apache Druid ignited new possibilities for tracking and querying data based on time, and document databases like MongoDB paved the way for handling unstructured data at unprecedented scales. Each system had its strengths, designed to handle specific workloads that relational databases struggled with.
However, while each offered different forms of data persistence and specialized capabilities, none came close to achieving the power of inference I began to see emerging in newer architectures. These databases could store, query, and retrieve data efficiently, but they needed the ability to derive meaningful insights autonomously. Their focus was on managing vast amounts of data, but they couldn’t make the leap into understanding and creating knowledge from that data on their own.
The New Era: RAG, Vector, and LLMs Leading the Charge
Then came the age of RAG (retrieval-augmented generation), vector databases, and large language models (LLMs). These architectures represented a seismic shift. They are not just about storing and querying data—they are about inference. Unlike graph, document, or relational databases, these systems have an inherent ability to understand context, make connections, and generate knowledge. RAG systems, for instance, combine the capabilities of retrieving relevant information from a dataset and augmenting that with real-time generation from LLMs.
Where traditional databases relied on static relationships between data points, vector databases introduced a new way of thinking about information. They stored data as embeddings, capturing meaning and relationships in ways that were multidimensional and context-aware. This architecture allowed for richer and more nuanced querying, making it possible to retrieve information based on conceptual similarity rather than rigid, predefined relationships.
LLMs, on the other hand, bring generative capabilities that go beyond mere retrieval. They can synthesize and create new information from existing data, performing tasks that were previously only possible for human experts. These systems learn, infer, and generate knowledge in real-time, making them far more powerful than anything I have previously worked with.
The Power of Integrated Knowledge and Intelligence
The integration of knowledge across enterprise systems, tools, and even cross-organizational data has become the ultimate goal. AI tools don’t just democratize access to data—they democratize intelligence itself. RAG, vector, and LLMs enable organizations to draw connections across vast amounts of unstructured data, integrating disparate systems into a cohesive, intelligent whole.
This shift in architecture is what sets modern AI apart. It can tap into enterprise systems like CRM, ERP, and other operational platforms while also reaching beyond organizational boundaries to synthesize knowledge from external sources. For instance, a healthcare organization can integrate patient data across hospital systems and augment it with predictive models based on public health trends, enabling more personalized and proactive patient care. Similarly, a financial institution can merge internal compliance data with external market insights, creating holistic risk models.
From Data Obsession to AI-Driven Innovation
My journey started with an obsession with relational databases, but as technology evolved, so did my understanding of the limits of different data persistence methods. From graph to time series and from document to distributed databases, each offered new capabilities but lacked the inferential power I was searching for. Today’s architectures—RAG, vector databases, and LLMs—go beyond what any of these earlier systems could achieve. They are designed not just to store or manage data but to generate actionable knowledge from it.
This new paradigm enables enterprises to go beyond data access to knowledge integration and intelligence-driven decision-making. It is the realization of what I have always hoped data systems could be—a foundation not just for understanding the past, but for anticipating and creating the future.
Read More: https://www.theiconicsuccess.com/the-evolution-from-relational-databases-to-ai-driven-knowledge-integration/
#IconsEdgeMagazine#GlobalBusinessMagazine#TETechnologyMagazines#IconsEdgeMedia#inspiringbusinessleaders
0 notes
Text
#graphrag#esg sustainability#semantic graph model#esg domains#knowledge graph llm#esg and nlp#graph rag llm
0 notes
Text
AI’s Trillion-Dollar Problem
New Post has been published on https://thedigitalinsider.com/ais-trillion-dollar-problem/
AI’s Trillion-Dollar Problem

As we enter 2025, the artificial intelligence sector stands at a crucial inflection point. While the industry continues to attract unprecedented levels of investment and attention—especially within the generative AI landscape—several underlying market dynamics suggest we’re heading toward a big shift in the AI landscape in the coming year.
Drawing from my experience leading an AI startup and observing the industry’s rapid evolution, I believe this year will bring about many fundamental changes: from large concept models (LCMs) expected to emerge as serious competitors to large language models (LLMs), the rise of specialized AI hardware, to the Big Tech companies beginning major AI infrastructure build-outs that will finally put them in a position to outcompete startups like OpenAI and Anthropic—and, who knows, maybe even secure their AI monopoly after all.
Unique Challenge of AI Companies: Neither Software nor Hardware
The fundamental issue lies in how AI companies operate in a previously unseen middle ground between traditional software and hardware businesses. Unlike pure software companies that primarily invest in human capital with relatively low operating expenses, or hardware companies that make long-term capital investments with clear paths to returns, AI companies face a unique combination of challenges that make their current funding models precarious.
These companies require massive upfront capital expenditure for GPU clusters and infrastructure, spending $100-200 million annually on computing resources alone. Yet unlike hardware companies, they can’t amortize these investments over extended periods. Instead, they operate on compressed two-year cycles between funding rounds, each time needing to demonstrate exponential growth and cutting-edge performance to justify their next valuation markup.
LLMs Differentiation Problem
Adding to this structural challenge is a concerning trend: the rapid convergence of large language model (LLM) capabilities. Startups, like the unicorn Mistral AI and others, have demonstrated that open-source models can achieve performance comparable to their closed-source counterparts, but the technical differentiation that previously justified sky-high valuations is becoming increasingly difficult to maintain.
In other words, while every new LLM boasts impressive performance based on standard benchmarks, a truly significant shift in the underlying model architecture is not taking place.
Current limitations in this domain stem from three critical areas: data availability, as we’re running out of high-quality training material (as confirmed by Elon Musk recently); curation methods, as they all adopt similar human-feedback approaches pioneered by OpenAI; and computational architecture, as they rely on the same limited pool of specialized GPU hardware.
What’s emerging is a pattern where gains increasingly come from efficiency rather than scale. Companies are focusing on compressing more knowledge into fewer tokens and developing better engineering artifacts, like retrieval systems like graph RAGs (retrieval-augmented generation). Essentially, we’re approaching a natural plateau where throwing more resources at the problem yields diminishing returns.
Due to the unprecedented pace of innovation in the last two years, this convergence of LLM capabilities is happening faster than anyone anticipated, creating a race against time for companies that raised funds.
Based on the latest research trends, the next frontier to address this issue is the emergence of large concept models (LCMs) as a new, ground-breaking architecture competing with LLMs in their core domain, which is natural language understanding (NLP).
Technically speaking, LCMs will possess several advantages, including the potential for better performance with fewer iterations and the ability to achieve similar results with smaller teams. I believe these next-gen LCMs will be developed and commercialized by spin-off teams, the famous ‘ex-big tech’ mavericks founding new startups to spearhead this revolution.
Monetization Timeline Mismatch
The compression of innovation cycles has created another critical issue: the mismatch between time-to-market and sustainable monetization. While we’re seeing unprecedented speed in the verticalization of AI applications – with voice AI agents, for instance, going from concept to revenue-generating products in mere months – this rapid commercialization masks a deeper problem.
Consider this: an AI startup valued at $20 billion today will likely need to generate around $1 billion in annual revenue within 4-5 years to justify going public at a reasonable multiple. This requires not just technological excellence but a dramatic transformation of the entire business model, from R&D-focused to sales-driven, all while maintaining the pace of innovation and managing enormous infrastructure costs.
In that sense, the new LCM-focused startups that will emerge in 2025 will be in better positions to raise funding, with lower initial valuations making them more attractive funding targets for investors.
Hardware Shortage and Emerging Alternatives
Let’s take a closer look specifically at infrastructure. Today, every new GPU cluster is purchased even before it’s built by the big players, forcing smaller players to either commit to long-term contracts with cloud providers or risk being shut out of the market entirely.
But here’s what is really interesting: while everyone is fighting over GPUs, there has been a fascinating shift in the hardware landscape that is still largely being overlooked. The current GPU architecture, called GPGPU (General Purpose GPU), is incredibly inefficient for what most companies actually need in production. It’s like using a supercomputer to run a calculator app.
This is why I believe specialized AI hardware is going to be the next big shift in our industry. Companies, like Groq and Cerebras, are building inference-specific hardware that’s 4-5 times cheaper to operate than traditional GPUs. Yes, there’s a higher engineering cost upfront to optimize your models for these platforms, but for companies running large-scale inference workloads, the efficiency gains are clear.
Data Density and the Rise of Smaller, Smarter Models
Moving to the next innovation frontier in AI will likely require not only greater computational power– especially for large models like LCMs – but also richer, more comprehensive datasets.
Interestingly, smaller, more efficient models are starting to challenge larger ones by capitalizing on how densely they are trained on available data. For example, models like Microsoft’s FeeFree or Google’s Gema2B, operate with far fewer parameters—often around 2 to 3 billion—yet achieve performance levels comparable to much larger models with 8 billion parameters.
These smaller models are increasingly competitive because of their high data density, making them robust despite their size. This shift toward compact, yet powerful, models aligns with the strategic advantages companies like Microsoft and Google hold: access to massive, diverse datasets through platforms such as Bing and Google Search.
This dynamic reveals two critical “wars” unfolding in AI development: one over compute power and another over data. While computational resources are essential for pushing boundaries, data density is becoming equally—if not more—critical. Companies with access to vast datasets are uniquely positioned to train smaller models with unparalleled efficiency and robustness, solidifying their dominance in the evolving AI landscape.
Who Will Win the AI War?
In this context, everyone likes to wonder who in the current AI landscape is best positioned to come out winning. Here’s some food for thought.
Major technology companies have been pre-purchasing entire GPU clusters before construction, creating a scarcity environment for smaller players. Oracle’s 100,000+ GPU order and similar moves by Meta and Microsoft exemplify this trend.
Having invested hundreds of billions in AI initiatives, these companies require thousands of specialized AI engineers and researchers. This creates an unprecedented demand for talent that can only be satisfied through strategic acquisitions – likely resulting in many startups being absorbed in the upcoming months.
While 2025 will be spent on large-scale R&D and infrastructure build-outs for such actors, by 2026, they’ll be in a position to strike like never before due to unrivaled resources.
This isn’t to say that smaller AI companies are doomed—far from it. The sector will continue to innovate and create value. Some key innovations in the sector, like LCMs, are likely to be led by smaller, emerging actors in the year to come, alongside Meta, Google/Alphabet, and OpenAI with Anthropic, all of which are working on exciting projects at the moment.
However, we’re likely to see a fundamental restructuring of how AI companies are funded and valued. As venture capital becomes more discriminating, companies will need to demonstrate clear paths to sustainable unit economics – a particular challenge for open-source businesses competing with well-resourced proprietary alternatives.
For open-source AI companies specifically, the path forward may require focusing on specific vertical applications where their transparency and customization capabilities provide clear advantages over proprietary solutions.
#000#2025#acquisitions#agents#ai#AI AGENTS#AI development#AI Infrastructure#Alphabet#amp#anthropic#app#applications#architecture#artificial#Artificial Intelligence#attention#benchmarks#BIG TECH#billion#bing#Building#Business#business model#calculator#Cerebras#challenge#Cloud#cloud providers#cluster
0 notes
Text
Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen – A Comprehensive Guide

In recent years, the world of artificial intelligence and data science has seen remarkable growth, particularly with advancements in retrieval-augmented generation (RAG) models. Among the most cutting-edge topics in this space are the use of Vector to Graph RAG LangChain Neo4j AutoGen, which has created waves in transforming the way we approach information retrieval, data structuring, and knowledge generation.
In this blog, we’ll dive into what Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen is all about, explore its core components, and why it’s crucial for developers and businesses looking to leverage AI-based solutions for more accurate and scalable applications.
Introduction to Advanced RAG
The concept of Retrieval-Augmented Generation (RAG) combines the best of both worlds: retrieval-based models and generative models. RAG leverages the power of large-scale pre-trained models and enhances them by including a retrieval component. This ensures that instead of generating responses purely from learned data, the model retrieves relevant information, leading to more accurate and contextually sound outputs.
At the heart of the Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen approach is the seamless integration between vector representations and graph databases such as Neo4j. In simple terms, this method allows data to be stored, retrieved, and represented as a graph structure while incorporating the benefits of LangChain for natural language processing and AutoGen for automatic data generation.
Vector to Graph RAG: A Powerful Shift
The transformation from vectors to graphs is a significant evolution in the RAG landscape. Vector embeddings are widely used in machine learning and AI to represent data in a high-dimensional space. These embeddings capture the semantic essence of text, images, and other types of data. However, vectors on their own don’t capture relationships between entities as well as graph structures do.
Graph RAG, on the other hand, enables us to represent data not only based on the content but also based on the relationships between various entities. For instance, in a customer service chatbot application, it’s important not just to retrieve the most relevant answer but to understand how different pieces of knowledge are connected. This is where Neo4j, a leading graph database, plays a pivotal role. By utilizing Neo4j, Vector to Graph RAG LangChain Neo4j AutoGen creates a rich knowledge network that enhances data retrieval and generative capabilities.
Why Neo4j?
Neo4j is one of the most popular graph databases used today, known for its ability to store and manage highly interconnected data. Its flexibility and performance in handling relationship-based queries make it ideal for graph RAG models. When used alongside LangChain, which excels in handling large language models (LLMs), and AutoGen, which automates the generation of relevant data, the synergy between these tools opens up a new frontier in AI.
Neo4j is particularly beneficial because:
Enhanced Relationships: Unlike traditional databases, Neo4j captures the rich connections between data points, offering a deeper layer of insights.
Scalability: It can scale horizontally, making it perfect for handling large amounts of data.
Real-Time Querying: With its graph-based querying system, Neo4j can retrieve data faster than conventional systems when relationships are involved.
LangChain’s Role in Advanced RAG
LangChain is a framework designed to work with large language models (LLMs) to simplify the process of combining language generation with external knowledge retrieval. In the context of Advanced RAG, LangChain adds significant value by serving as a bridge between the LLMs and the retrieval mechanism.
Imagine a scenario where a model needs to generate a customer support response. Instead of relying solely on pre-trained knowledge, LangChain can retrieve relevant data from Neo4j based on the query and use the LLM to generate a coherent, contextually appropriate answer. This combination boosts both the accuracy and relevance of the responses, addressing many of the limitations that come with generative-only models.
LangChain offers key advantages such as:
Seamless integration with LLMs: By utilizing Vector to Graph RAG LangChain Neo4j AutoGen, the generated content is more contextually aware and grounded in real-world data.
Modular framework: LangChain allows developers to customize components like retrieval mechanisms and data sources, making it a flexible solution for various AI applications.
AutoGen: The Future of AI-Generated Content
The final pillar in the Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen framework is AutoGen, which, as the name suggests, automates the generation of data. AutoGen allows for real-time generation of both text-based and graph-based data, significantly reducing the time it takes to build and scale AI models.
With AutoGen, developers can automate the process of building and updating knowledge graphs in Neo4j, thereby keeping the data fresh and relevant. This is particularly useful in dynamic industries where information changes rapidly, such as healthcare, finance, and e-commerce.
Applications of Vector to Graph RAG LangChain Neo4j AutoGen
The combination of Vector to Graph RAG LangChain Neo4j AutoGen has far-reaching applications. Here are a few real-world examples:
Customer Support Chatbots: By using this system, businesses can enhance their customer support services by not only retrieving the most relevant information but also understanding the relationship between customer queries, products, and services, ensuring more personalized and effective responses.
Recommendation Engines: Graph-based RAG models can improve the accuracy of recommendation systems by understanding the relationships between user behavior, preferences, and product offerings.
Healthcare Knowledge Graphs: In healthcare, creating and maintaining up-to-date knowledge graphs using Neo4j can significantly enhance diagnosis and treatment recommendations based on relationships between medical conditions, treatments, and patient data.
Optimizing SEO for “Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen”
To make sure this blog ranks well on search engines, we have strategically included related keywords like:
Retrieval-Augmented Generation (RAG)
Graph-based RAG models
LangChain integration with Neo4j
Vector embeddings
Neo4j for AI
AutoGen for automated graph generation
Advanced AI frameworks
By using variations of the keyphrase Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen and related terms, this blog aims to rank for multiple keywords across the board. Ensuring keyphrase density throughout the blog and placing the keyphrase in the introduction gives this content the SEO boost it needs to rank on SERPs.
Conclusion: Why Adopt Advanced RAG?
The landscape of AI is evolving rapidly, and methods like Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen are pushing the boundaries of what’s possible. For developers, data scientists, and businesses looking to harness the power of AI for more accurate, scalable, and contextually aware solutions, this combination offers an incredible opportunity.
By integrating vector embeddings, graph databases like Neo4j, and frameworks like LangChain and AutoGen, organizations can create more robust systems for knowledge retrieval and generation. Whether you’re building the next-generation chatbot, recommendation engine, or healthcare solution, this advanced RAG model offers a scalable and powerful path forward.
0 notes
Link
Large Language Models (LLMs), like ChatGPT and GPT-4 from OpenAI, are advancing significantly and transforming the field of Natural Language Processing (NLP) and Natural Language Generation (NLG), thus paving the way for the creation of a plethora o #AI #ML #Automation
0 notes
Text
Graph RAG: Unleashing the Power of Knowledge Graphs With LLM
http://securitytc.com/SywW8r
0 notes
Text
LM Studio Improves LLM with CUDA 12.8 & GeForce RTX GPUs

LM Studio Accelerates LLM with CUDA 12.8 and GeForce RTX GPUs
The latest desktop application update improves model controls, dev tools, and RTX GPU performance.
As AI use cases proliferate, developers and hobbyists want faster and more flexible ways to run large language models (LLMs), from document summarisation to custom software agents.
Running models locally on PCs with NVIDIA GeForce RTX GPUs enables high-performance inference, data privacy, and AI deployment and integration management. Free programs like LM Studio let users examine and operate with LLMs on their own hardware.
LM Studio is a popular local LLM inference application. Based on the fast llama.cpp runtime, the application allows models to run offline and be utilised as OpenAI-compatible API endpoints in custom workflows.
LM Studio 0.3.15 uses CUDA 12.8 to boost RTX GPU model load and response times. The upgrade adds developer-focused features like a revised system prompt editor and “tool_choice” tool usage.
The latest LM Studio improvements improve usability and speed, enabling the highest throughput on RTX AI PCs. This leads to faster reactions, snappier interactions, and better local AI development and integration tools.
AI Acceleration Meets Common Apps
LM Studio can be used for light experimentation and significant integration into unique processes due to its versatility. Developer mode permits desktop chat or OpenAI-compatible API calls to models. Local LLMs can be integrated with custom desktop agents or processes in Visual Studio Code.
The popular markdown-based knowledge management tool Obsidian may be integrated with LM Studio. Local LLMs in LM Studio allow users to query their notes, produce content, and summarise research using community-developed plug-ins like Text Generator and Smart Connections. These plug-ins enable fast, private AI interactions without the cloud by connecting to LM Studio's local server.
Developer enhancements in 0.3.15 include an updated system prompt editor for longer or more sophisticated prompts and more accurate tool usage management through the “tool_choice” option.
The tool_choice argument lets developers require a tool call, turn it off, or allow the model decide how to connect with external tools. Adding flexibility to structured interactions, retrieval-augmented generation (RAG) workflows, and agent pipelines is beneficial. Together, these upgrades improve LLM use cases for developers in experimental and production.
LM Studio supports Gemma, Llama 3, Mistral, and Orca open models and quantisation formats from 4-bit to full precision.
Common use cases include RAG, document-based Q&A, multi-turn chat with long context windows, and local agent pipelines. Local inference servers run by the NVIDIA RTX-accelerated llama.cpp software package allow RTX AI PC users to simply integrate local LLMs.
LM Studio gives you full control, speed, and privacy on RTX, whether you're optimising a modest PC for efficiency or a big desktop for throughput.
Maximise RTX GPU Throughput
LM Studio's acceleration relies on the open-source runtime llama.cpp for consumer hardware inference. NVIDIA worked with LM Studio and llama.cpp to increase RTX GPU performance.
Important optimisations include:
CUDA graph enablement reduces CPU overhead and boosts model throughput by 35% by integrating GPU operations into a CPU call.
Flash attention CUDA kernels can boost throughput by 15% by improving LLM attention handling in transformer models. This improvement allows longer context windows without increasing memory or computing power.
Supports the newest RTX architectures: LM Studio's CUDA 12.8 update works with high-end PCs, so clients can deploy local AI processes from laptops. all RTX AI PCs, from GeForce 20 Series to NVIDIA Blackwell-class GPUs.
LM Studio automatically changes to CUDA 12.8 with a compatible driver, improving model load times and performance.
These improvements speed up response times and smooth inference on all RTX AI PCs, from small laptops to large desktops and workstations.
Utilise LM Studio
Linux, macOS, and Windows have free LM Studio. The recent 0.3.15 release and continual optimisations should improve local AI performance, customisation, and usability, making it faster, more versatile, and easier to use.
Developer mode offers an OpenAI-compatible API, and desktop chat allows users import models.
Start immediately by downloading and launching the latest LM Studio.
Click the left magnifying glass to open Discover.
See the CUDA 12 llama.cpp (Windows) runtime in the availability list after selecting Runtime choices on the left side. Click “Download and Install”.
After installation, select CUDA 12 llama.cpp (Windows) from the Default Selections selection to set LM Studio to use this runtime.
To optimise CUDA execution in LM Studio, load a model and click the gear icon to the left of it to open Settings.
Drag the “GPU Offload” slider to the right to offload all model layers to the GPU, then enable “Flash Attention” from the selection menu.
Local NVIDIA GPU inference is possible if these functions are enabled and configured.
LM Studio supports model presets, quantisation formats, and developer options like tool_choice for exact inference. The llama.cpp GitHub project is continually updated and evolving with community and NVIDIA performance enhancements for anyone who wants to contribute.
LM Studio 0.3.15 offers RTX 50-series GPUs and API tool utilisation improvements
A stable version of LM Studio 0.3.15 is available. This release supports NVIDIA RTX 50-series GPUs (CUDA 12) and UI changes include a revamped system prompt editor. Added possibility to log each fragment to API server logs and improved tool use API support (tool_choice parameter).
RTX 50-series GPU CUDA 12 compatibility
With llama.cpp engines, LM Studio supports RTX 50-series GPUs CUDA 12.8 for Linux and Windows. As expected, this improvement speeds up RTX 50-series GPU first-time model load times. LM Studio will update RTX 50-series GPUs to CUDA 12 if NVIDIA drivers are acceptable.
The minimum driver version is:
Windows version 551.61+
Linux: 550.54.14 minimum
LM Studio will immediately update to CUDA 12 if the driver version matches your RTX 50-series GPU. LM Studio uses CUDA 11 even with incompatible RTX 50 GPU drivers. Controlled by Command+Shift+R.
New System Prompt Editor UI
System suggestions change model behaviour well. They range from a few words to several pages. LM Studio 0.3.15 adds a larger visual space for modifying long prompts. The sidebar's little prompt editor works.
Improved Tool Use API Support
The OpenAI-like REST API now supports tool_choice, which helps you configure model tool use. The tool_choice argument has three values:
“tool_choice”: “none” means the model will call no tools.
“tool_choice”: “auto” The model decides whether to invoke tools with the option.
tool_choice: “required” Just output tools (llama.cpp engines)
NVIDIA also fixed LM Studio's OpenAI-compatibility mode bug that prohibited the chunk “finish_reason” from being changed to “tool_calls”.
Preview Community Presets
Presets combine system prompts with model parameters.
Since LM Studio 0.3.15, you can download and share user-made presets online. Additionally, you can like and fork other settings.
Settings > General > Enable publishing and downloading presets activates this option.
Right-clicking a sidebar setting reveals a “Publish” button once activated. Share your preset with the community.
#CUDA128#LMStudio#CUDA12#LMStudio0315#RTX50seriesGPUs#NVIDIAGeForceRTXGPUs#technology#TechNews#technologynews#news#govindhtech
0 notes